Google Cloud Storage
Overview
Google Cloud Storage is often used along with CloudML to manage and serve training data. This article provides details on:
Copying and synchronizing files between your local workstation and Google Cloud.
Reading data from Google Cloud Storage buckets from within a training script.
Varying data source configuration between local script development and CloudML training.
Copying Data
Google Cloud Storage is organized around storage units named “buckets”, which are roughly analogous to filesystem directories. You can copy data between your local system and cloud storage using the gs_copy() function. For example:
library(cloudml)
# copy from a local directory to a bucket
gs_copy("training-data", "gs://quarter-deck-529/training-data")
# copy from a bucket to a local directory
gs_copy("gs://quarter-deck-529/training-data", "training-data")You can also use the gs_rsync() function to syncrhonize a local directory and a bucket in Google Storage (this is much more efficient than copying the data each time):
# synchronize a bucket and a local directory
gs_rsync("gs://quarter-deck-529/training-data", "training-data")Note that to use these functions you need to import the cloudml package with library(cloudml) as illustrated above.
Reading Data
Some TensorFlow APIs can take gs:// URLs directly however most often you will need a local filesystem path to a data source in order to read it. If you want to store data in Google Storage but still use it with APIs that require local paths you can use the gs_local_dir() function to provide the local path.
For example, this code reads CSV files from Google Storage:
library(cloudml)
library(readr)
data_dir <- gs_local_dir("gs://quarter-deck-529/training-data")
train_data <- read_csv(file.path(data_dir, "train.csv"))
test_data <- read_csv(file.path(data_dir, "test.csv"))Under the hood this function will rsync data from Google Storage as required to provide the local filesystem interface to it.
Here’s another example which creates a Keras image data generator from a bucket:
train_generator <- flow_images_from_directory(
gs_local_dir("gs://quarter-deck-529/images/train"),
image_data_generator(rescale = 1/255),
target_size = c(150, 150),
batch_size = 32
class_mode = "binary"
)Note that if the path passed to gs_local_dir() is from the local filesystem it will be returned unmodified.
Data Source Configuration
It’s often useful to do training script development with a local subsample of data that you’ve extracted from the complete set of training data. In this configuration, you’ll want your training script to dynamically use the local subsample during development then use the complete dataset stored in Google Cloud Storage when running on CloudML. You can accomplish this with a combination of training flags and the gs_local_dir() function described above.
Here’s a complete example. We start with a training script that declares a flag for the location of the training data:
library(keras)
library(cloudml)
# define a flag for the location of the data directory
FLAGS <- flags(
flag_string("data_dir", "data")
)
# determine the location of the directory (during local development this will
# be the default "data" subdirectory specified in the FLAGS declaration above)
data_dir <- gs_local_dir(FLAGS$data_dir)
# read the data
train_data <- read_csv(file.path(FLAGS$data_dir, "train.csv"))Note that the data_dir R variable is computed by passing FLAGS$data_dir to the gs_local_dir() function. This enables it to take on a dynamic value depending upon the training environment.
The way to vary this value when running on CloudML is by adding a flags.yml configuration file to your project directory. For example:
flags.yml
cloudml:
data_dir: "gs://quarter-deck-529/training-data"With the addition of this config file, your script will resolve the data_dir flag to specified the Google Storage bucket, but only when it is running on CloudML.
Managing Storage
You can view and manage data within Google Cloud Storage buckets using either a web based user-interface or via command line utilities included with the Google Cloud SDK.
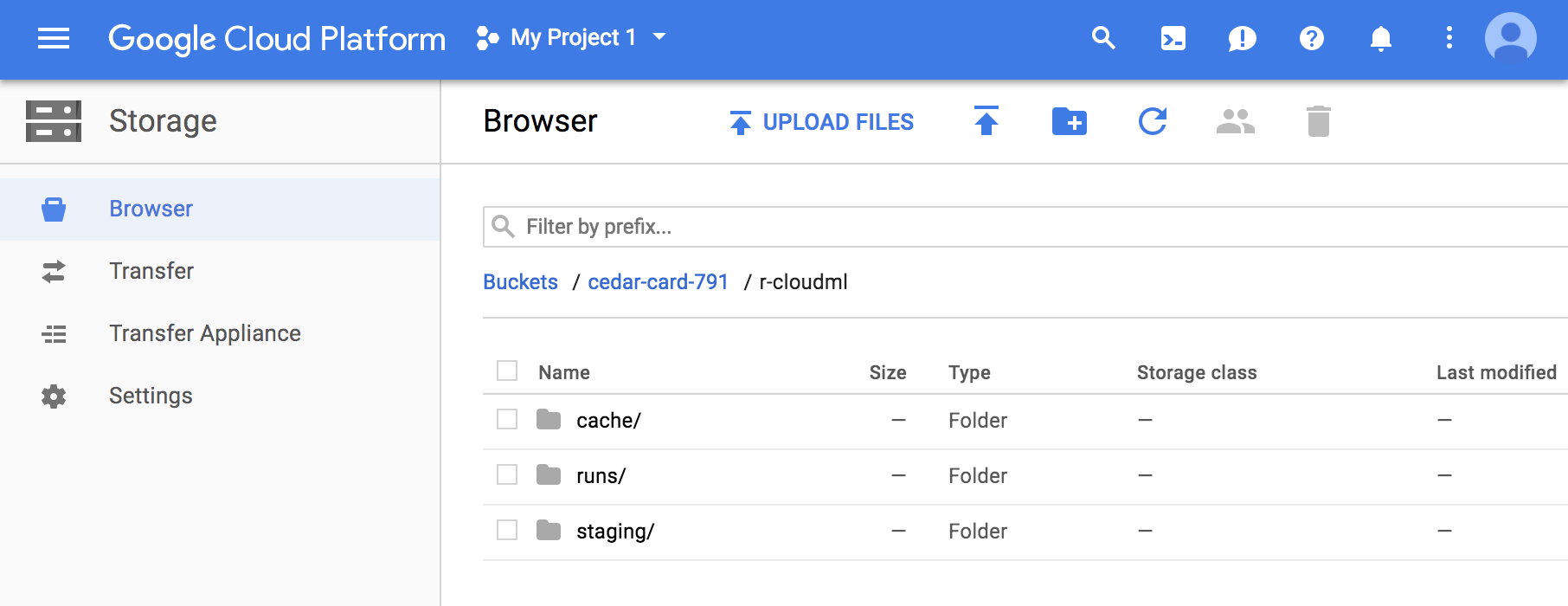
Google Storage Browser
To access the web-bqsed UI, navigate to https://console.cloud.google.com/storage/browser.
Here’s what the storage browser looks like for a sample project:
Google Cloud SDK
The Google Cloud SDK includes the gsutil utility program for managing cloud storage buckets. Documentation for gsutil can be found here: https://cloud.google.com/storage/docs/gsutil.
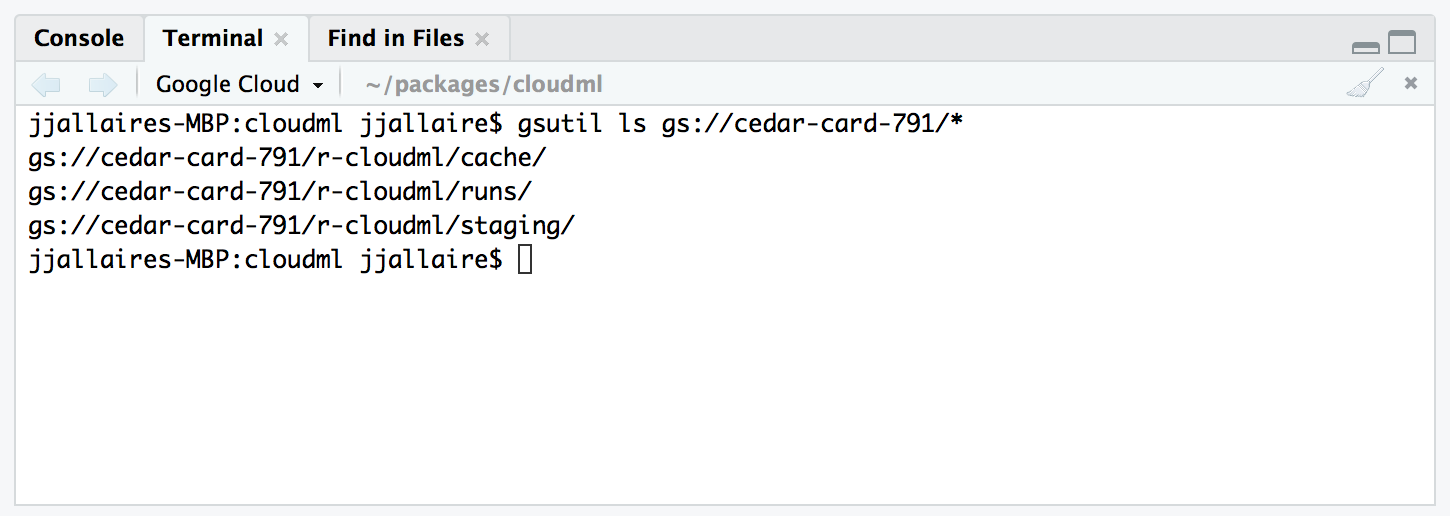
You use gsutil from within a terminal. If you are running within RStudio v1.1 or higher you can activate a terminal with the gcloud_terminal() function:
Here is an example of using the gsutil ls command to list the contents of a bucket within a terminal: