Gallery
The articles below provide in-depth examples of using TensorFlow with R. Most include detailed explanatory narrative as well as coverage of ancillary tasks like data preprocessing and visualization. They are a great resource for taking the next step after you’ve learned the basics.
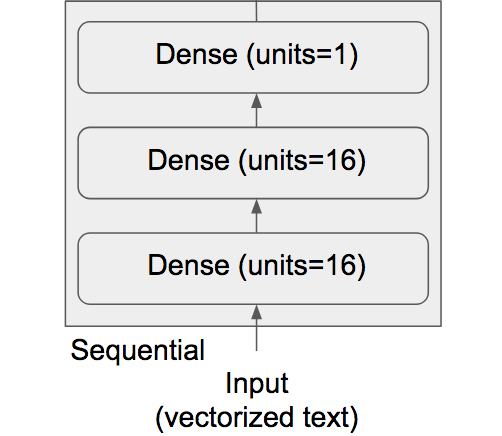 |
Deep Learning for Text Classification In this example, you’ll learn to classify movie reviews as positive or negative, based on the text content of the reviews. You’ll work with the IMDB dataset: a set of 50,000 highly polarized reviews from the Internet Movie Database. They’re split into 25,000 reviews for training and 25,000 reviews for testing, each set consisting of 50% negative and 50% positive reviews. |
 |
Image Classification on Small Datasets Having to train an image-classification model using very little data is a common situation, which you’ll likely encounter in practice if you ever do computer vision in a professional context. In this example, we’ll focus on classifying images as dogs or cats, in a dataset containing 4,000 pictures of cats and dogs. We’ll use 2,000 pictures for training – 1,000 for validation, and 1,000 for testing. |
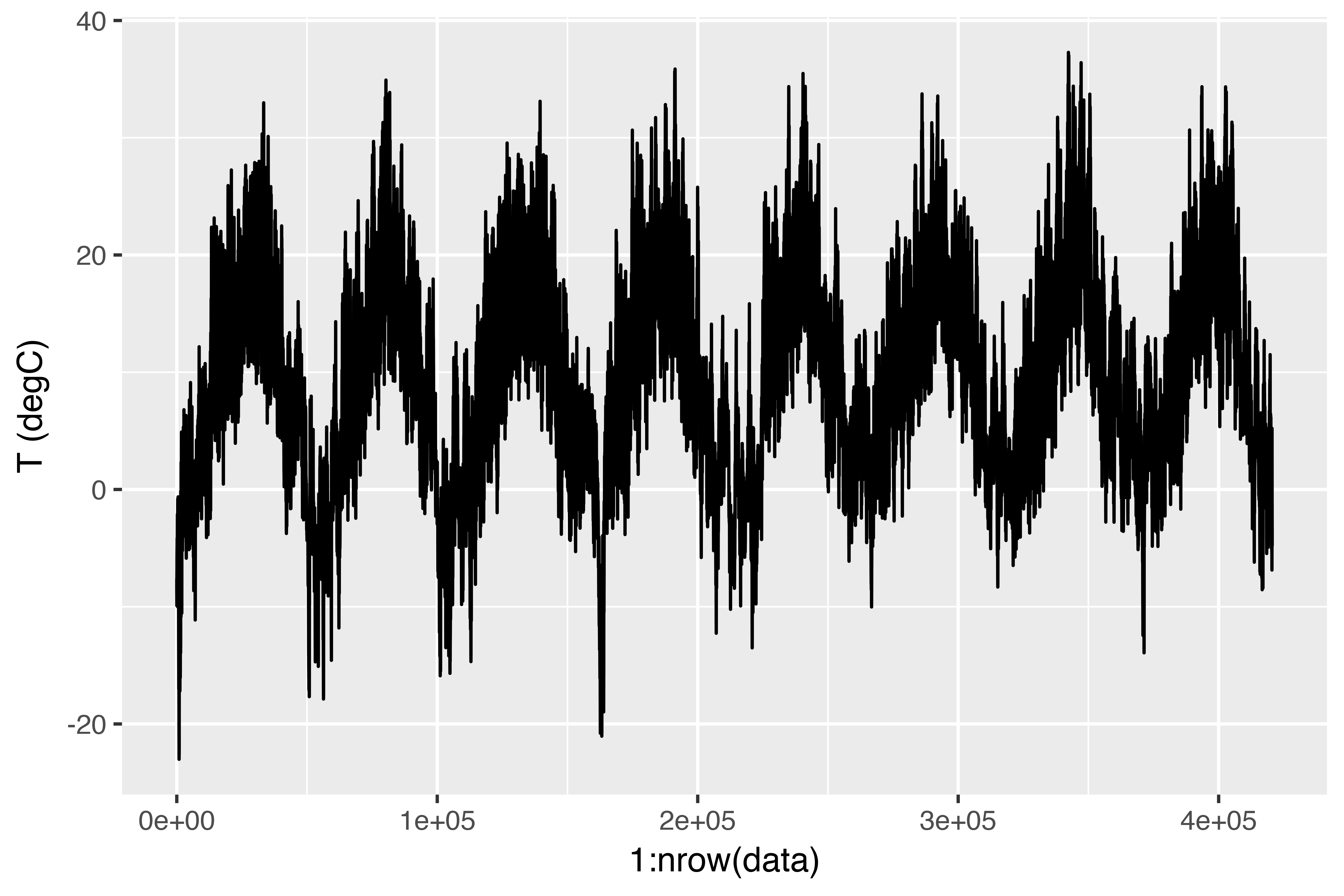 |
Time Series Forecasting with Recurrent Neural Networks In this example, we use a a temperature-forecasting problem to demonstrate three advanced techniques for improving the performance and generalization power of recurrent neural networks. This is a fairly challenging problem that exemplifies many common difficulties encountered when working with time series. |
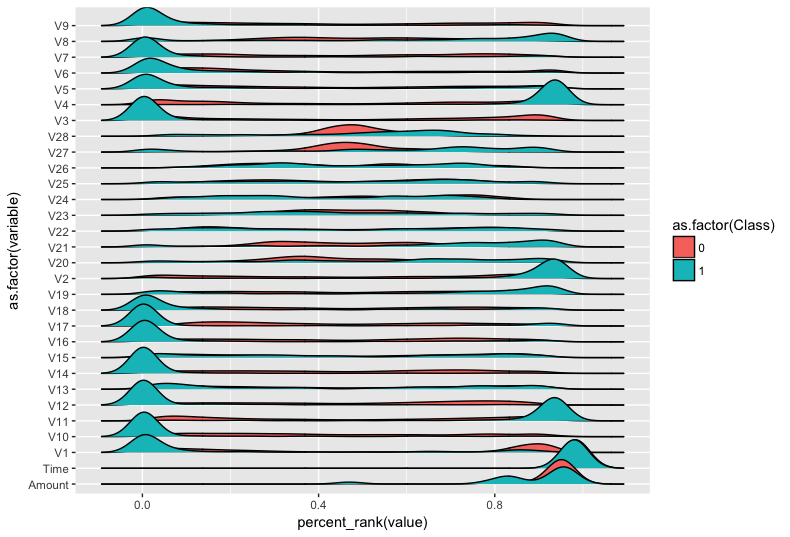 |
Predicting Fraud with Autoencoders and Keras In this example we train an autoencoder to detect credit card fraud. We will also demonstrate how to train Keras models in the cloud using CloudML. The basis of our model will be the Kaggle Credit Card Fraud Detection dataset, which was collected during a research collaboration of Worldline and the Machine Learning Group of ULB (Université Libre de Bruxelles) on big data mining and fraud detection. |
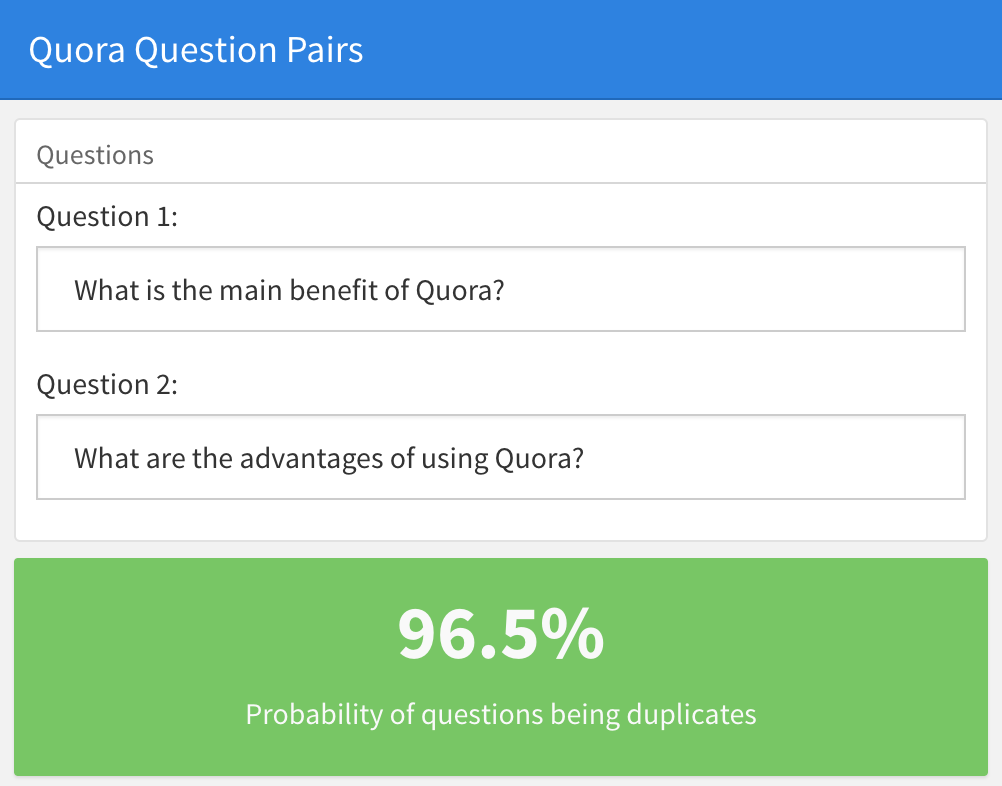 |
Classifying Duplicate Questions from Quora In this example we will use Keras to classify duplicated questions from Quora. The dataset first appeared in the Kaggle competition Quora Question Pairs and consists of approximately 400,000 pairs of questions along with a column indicating if the question pair is considered a duplicate. The idea is to learn a function that maps input patterns into a target space such that a similarity measure in the target space approximates the “semantic” distance in the input space. |
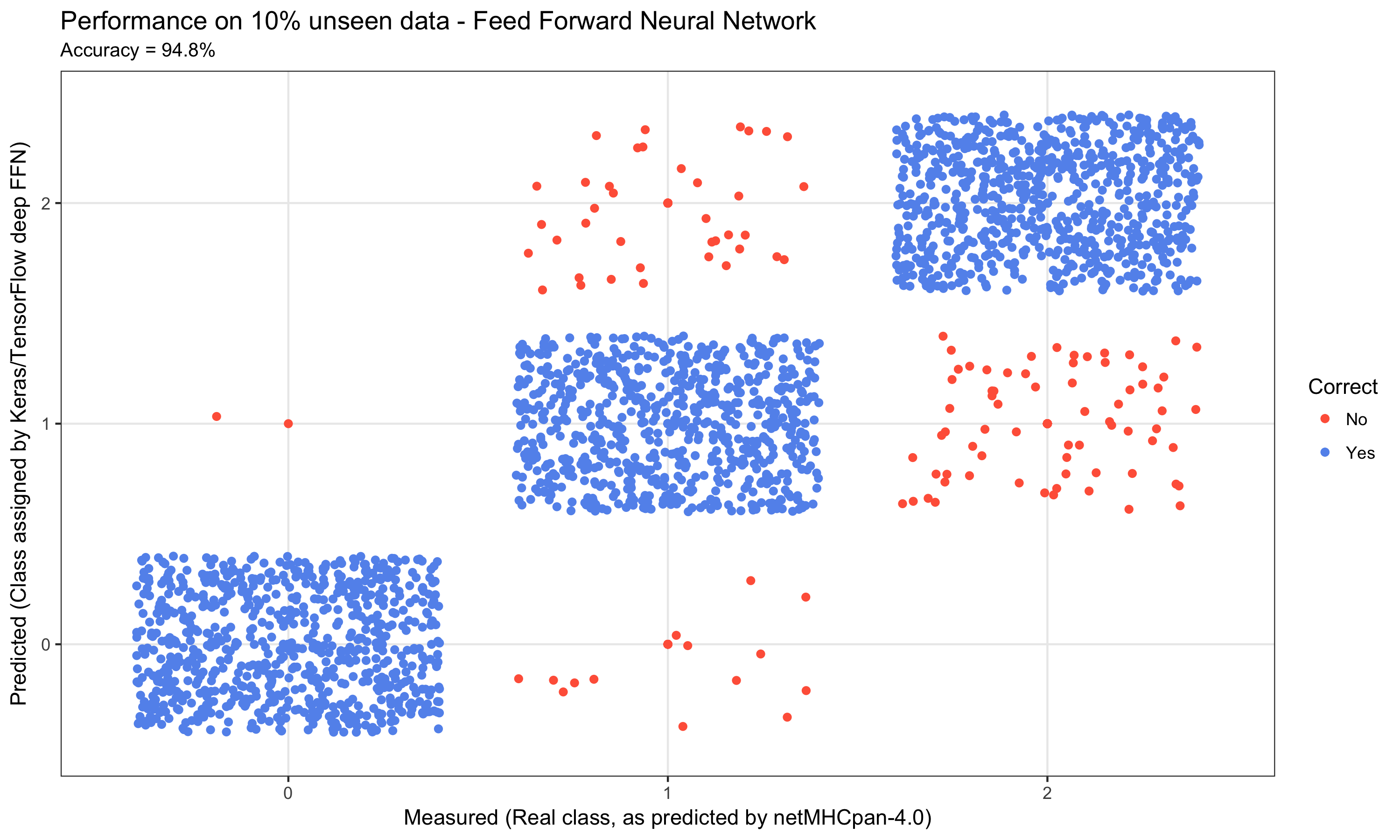 |
Deep Learning for Cancer Immunotherapy Adoptive T-cell therapy is a form of cancer immunotherapy that aims to isolate tumor infiltrating T-cells and reintroduce them into the body to fight cancer. By analyzing the tumor genetics, relevant peptides can be identified and depending on the patients particular type of MHCI, we can predict which pMHCI are likely to be present in the tumor in the patient and thus which pMHCIs should be used to activate the T-cells. |
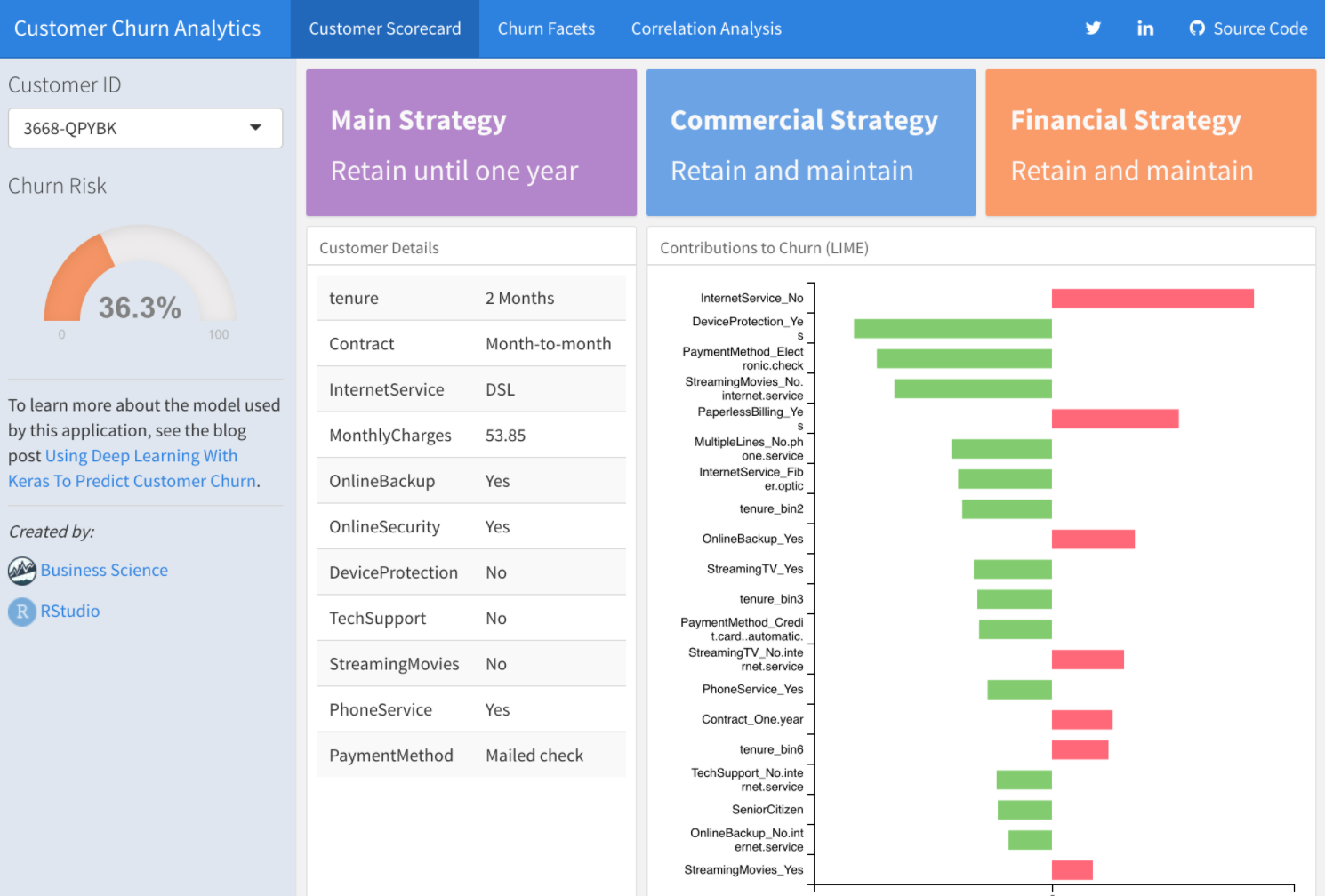 |
Deep Learning To Predict Customer Churn In this example we show you how to use keras to develop a sophisticated and highly accurate deep learning model of customer churn in R. We walk you through the preprocessing steps, investing time into how to format the data for Keras. We inspect the various classification metrics, and show that an un-tuned ANN model can easily get 82% accuracy on the unseen data. |
 |
Ship Recognition in Satellite Imagery with CNNs This article explores image classification using convolutional nueral networks (CNNs) by analyzing a dataset of 2,800 cargo ships in San Francisco Bay. CNNs are a class of deep, feed-forward artificial neural networks designed for solving problems like image/video/audio recognition, and object detection. |
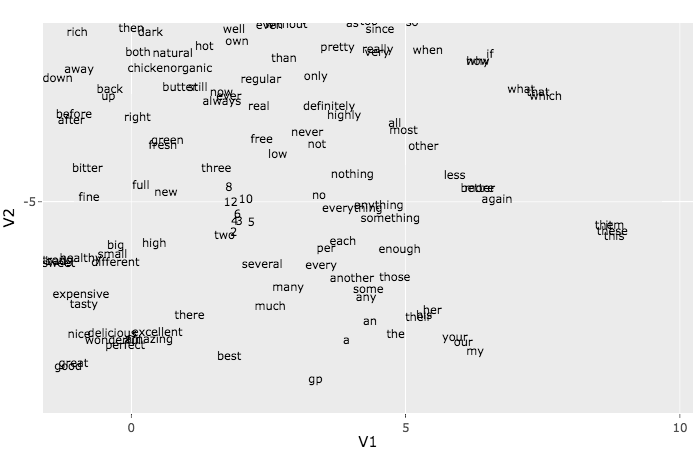 |
Word Embeddings with Keras Word embedding is a method used to map words of a vocabulary to dense vectors of real numbers where semantically similar words are mapped to nearby points. In this article we will implement the skip-gram model created by Mikolov et al. The skip-gram model is a flavor of word2vec, a class of computationally-efficient predictive models for learning word embeddings from raw text. |